
Is DevOps Related to DataOps?


By Carol Jang & Jove Kuang
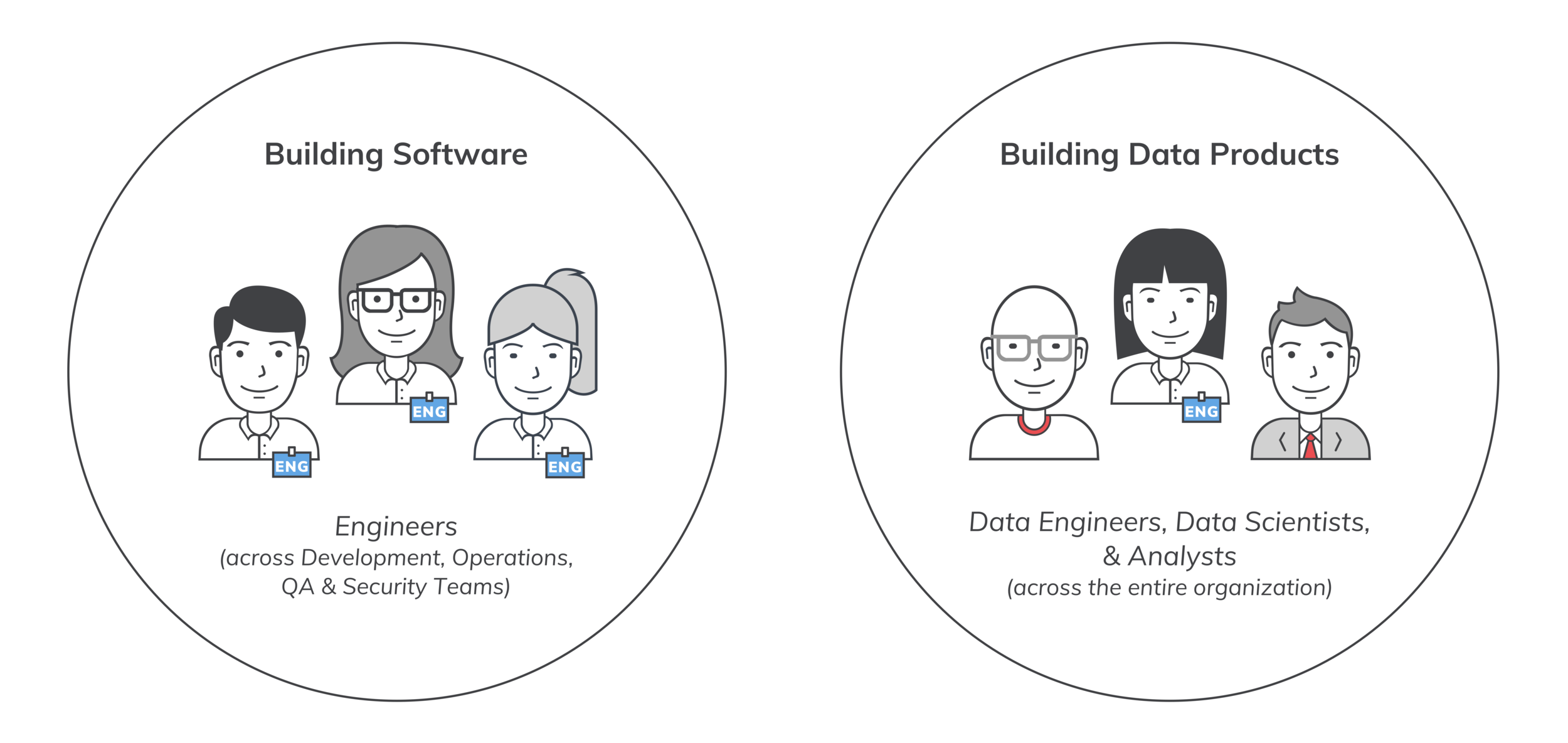
Similar to how DevOps changed the way we develop software, DataOps is changing the way we create data products. By leveraging DevOps methodologies, teams have achieved speed, quality, and flexibility by employing a Delivery Pipeline and Feedback Loop to create and maintain software products. DataOps employs a similar workflow to achieve the same goals for teams building data products. While both are based on agile frameworks, they differ greatly in their implementation of build, test, and release. DataOps requires the coordination of ever-changing data and everyone who works with data across an entire business, whereas DevOps requires coordination among software developers and IT.

Based on: https://aws.amazon.com/devops/what-is-devops/
DevOp vs. DataOps Delivery Pipelines
1. Build (Speed)
To build a new piece of software, you need a software developer (or a team of them) who is proficient in the relevant programming languages and who understands the purpose of the software in terms of features and functions. For example, let’s say you need a button that uploads documents. The developer building this just needs to know the desired function. They don’t need to understand the contents of the document being uploaded or the business context of why it’s being uploaded in the first place. The developer’s responsibility is just to put the right code in place to make sure the button gets the document uploaded.
When building a new data product, the parameters of success are no longer technical features and functions but business metrics and goals that not only require expertise in the relevant coding languages but also a deep understanding of the underlying data and business context. The contents of every data file and how it’s used becomes massively important! For this reason, data engineers can’t build data products in a silo; they must collaborate with data scientists and analysts to understand the business context.
Let’s take a social media company that wants to calculate its user lifetime value (LTV) as an example. To start, analysts and data scientists must apply their business expertise to determine what data sets are needed to calculate user LTV and request this data from data engineering. Data engineers need to prepare and clean the data into a usable format before data scientists and analysts can start to build the right models and analyses to calculate user LTV. Lastly, data engineers need to orchestrate the jobs and set the right infrastructure configurations to deliver the end results. All in all, generating user LTV as a data product combines the skills and knowledge of data engineers, data scientists, and analysts to determine
which data is relevant;
what code and tools are needed to retrieve, connect, and transform the data; and
how to extract valuable insights from the data to help the business.
These constant pass-offs during development can hinder speed and efficiency. Thus, winning DataOps methodologies must be designed with cross-team collaboration in mind to meet the growing demands for data across the business.
2. Test (Quality)
Developers test their software by observing whether the correct output is produced based on the given input. There is a clear cause and effect relationship to help determine the quality of the software. Based on the previous software example, if clicking the button uploads the selected document to the correct location, the test is a success.

Now, if we were testing the user LTV calculation in the previous data product example, how would we determine success if the company has never computed its user LTV before? The test isn’t over simply if the data product spits out a number. That number must be validated. This can be done by comparing the results to that of another data product calculating the same metric using a different methodology or via other cross-validation tests.

The quality of the data product is unclear until there is other evidence to support its results. Oftentimes, more iterations are required to fine-tune the results as data changes and more evidence is uncovered. The ability to iterate and maintain quality is critical to the value a data product delivers.
3. Release (Flexibility)

When developers release new software, the deployment is deemed a success once all the features are live and in-use. The software has reached the end of the Delivery Pipeline and enters a Feedback Loop during which developers monitor and plan for the next update or version. On the other hand, the end users simply enjoy the features and may or may not choose to provide feedback; their involvement in the Feedback Loop is indirect and voluntary.
With data products, the inputs and outputs are constantly changing; just because a data product worked during test and release, doesn’t mean it will continue to work. Schemas change, new columns get added, labeling shifts over time. As the data inevitably changes, so should the data product. Also, as the business becomes smarter, so should the data product -- possibly by adding other data points to refine its analyses. The individuals who best understand all these changes also happen to be the end users: data scientists and analysts. Thus, in DataOps, end users’ involvement in the Feedback Loop is direct and mandatory; they must work closely with data engineers to ensure the data products continue to improve and run smoothly.
In the previous data product example, if the data analytics team at the social media company learned that a user’s number of active followers has a significant impact on their LTV, they will want to add this variable to the user LTV calculation. In this case, they will work closely with the data engineering team to make sure the right data needed to calculate the number of active followers per user is added to the data product.
From a data engineering perspective, without DataOps, changes like this can involve lengthy re-designs, re-models, major reprocessing, and backfilling of the data product. With DataOps, there’s an understanding that things change; a data product is never truly “complete” and flexibility is a must-have for it to continue being valuable to the business.
To summarize, DataOps and DevOps are different because the former optimizes for data products and the latter optimizes for software. Building a successful data product requires different areas of expertise and, therefore, is a cross-team collaboration. Testing data products requires finding evidence to validate the results and fine-tuning to achieve the right results. And, lastly, releasing data products is an ongoing, collaborative effort because the data will change and the data product must adapt to accommodate those changes.
But that’s just our two-cents. What differences have you experienced when implementing DataOps vs. DevOps? Care to share?